수십억의 유저를 가진 IT 서비스들은
간단한 DB 읽기 요청도 정말 많이 들어올텐데 그럼 DB가 폭발할 수 밖에 없습니다.
하지만 DB없이도 몇억건의 자료들 검색을 빠르게 할 수 있는 방법이 하나 있습니다.

DB에 있는 데이터들을 다 꺼낸 다음에
꺼낸 데이터들을 짜부시키고 겹쳐서 메모리에 저장해두는거에요.
그럼 1. 압축을 통해 용량도 절약되고 2. 검색작업도 매우 빠르게 가능해집니다.
학교에선 잘 안가르쳐주는 실전 노가다꾼들만 쓰던 자료구조인데
이걸 블룸필터(Bloom Filter)라고 부릅니다.

예시로 좋아하는 포켓몬 이름들을 몇개 골라봅시다.
이런 이름들을 블룸필터에 저장해두려면 어떻게 하냐면

대충 이런 식입니다.
0과 1을 저장할 수 있는 칸을 여러개 만들어두고
저장하고 싶은 자료들을 0과 1로 변환을 한 다음에
그걸 서로 겹쳐서 저장해두면 끝입니다.
0과 1로 변환은 어떻게 하냐면 해시함수라는걸 씁니다.
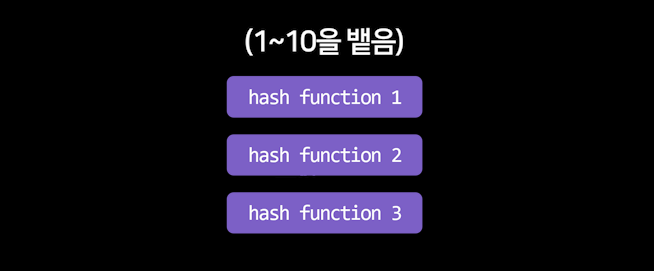
해시함수는 그냥 숫자를 넣으면 어떤 규칙에 따라 다른 숫자로 바꿔주는 함수를 해시함수라고 부를 뿐입니다.
아무튼 칸이 10개나 있으면 1부터 10까지의 숫자를 하나 뱉어주는 해시 함수를 몇개 만들어둡니다.
저는 3개 만들어뒀구요
그 다음에 글자를 3개의 함수에 전부 집어넣어봅니다.
아스키를 쓰든 해서 글자를 숫자로 바꿔서 넣으면 되지 않을까요.

그럼 1부터 10까지의 숫자 3개가 나오게 됩니다.
예를 들어 1 3 7 이런 숫자가 나왔다고 칩시다.
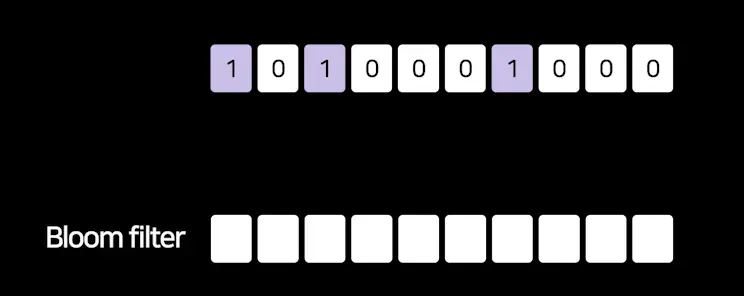
그럼 1번째, 3번째, 7번째 칸을 1로 마킹한 다음에 그걸 블룸필터에 넣습니다.
이게 glaceon이라는 단어를 블룸필터에 저장하는 과정 끝입니다.
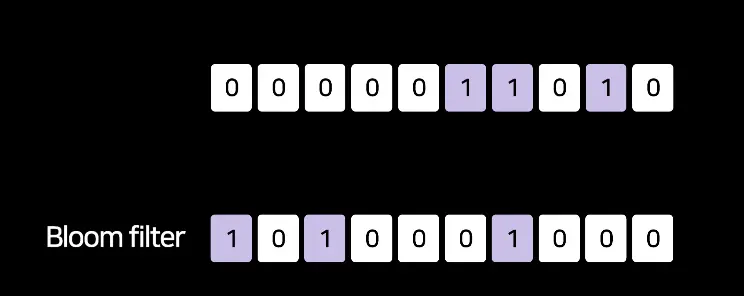
다른 단어를 저장하고 싶으면 똑같은 작업을 반복하면 됩니다.
근데 블룸필터에 집어넣을 때 똑같은 자리에 1이 이미 채워져있으면
그냥 남자답게 덮어쓰기 하면 되겠습니다.
자료들을 압축하고 뭉쳐서 더러운 덩어리로 저장하는 자료구조인데 심플하죠?
자료검색
더러운 덩어리에서 자료 검색을 하고 싶으면 어떻게 하게요?
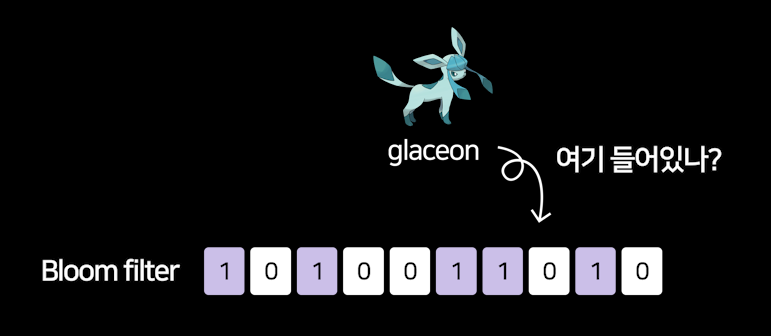
예를 들어 glaceon이라는 단어가 들어있는지 찾고싶으면
1. 아까랑 똑같이 glaceon을 해싱함수들에 넣어서 숫자 3개를 뽑고
2. 그 숫자들로 10개 칸에 1을 표시하고
3. 덩어리와 똑같은 위치에 1이 있는지 비교해봅니다.
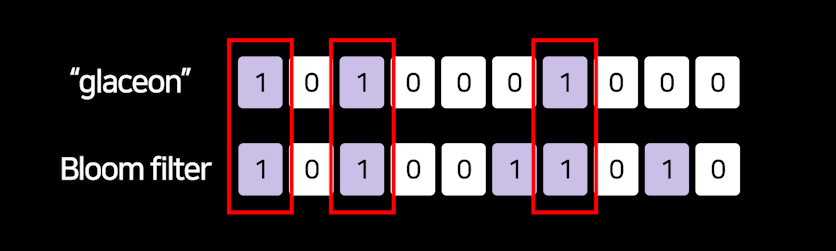
glaceon과 똑같은 위치에 1이 채워져있으면 자료가 블룸필터에 있다고 판단하면 되겠습니다.
똑같은 위치에 1이 없으면 자료가 블룸필터에 없다고 판단하면 되겠습니다.
그리고 이건 CPU 입장에서 비트 연산으로 엄청 빠르게 연산이 가능합니다.
O(1) 만큼 빠르게 찾을 수가 있는 건데 저장한 자료가 많아져도 거의 똑같은 시간 안에 검색이 가능해서 그렇습니다.
뭔지 모르겠으면 그냥 1등으로 좋은거라고 생각하시면 되겠습니다.
심지어 자료를 0과 1로 짜부시키고 서로 겹쳐서 저장을 하기 때문에
요즘 메모리값도 비싼데 해시테이블 이런거 쓰는거보다 메모리 용량도 많이 줄일 수 있습니다.
단점
남자답고 좋은 자료구조인데 최대 단점이 하나 있습니다.
일단 "블룸필터에 자료가 없다"고 판정되면 데이터가 진짜 없는게 맞습니다.
근데 "블룸필터에 자료가 있다"고 판정되면 약간 슈뢰딩거식으로 자료가 있을 수도 있고 없을 수도 있습니다.
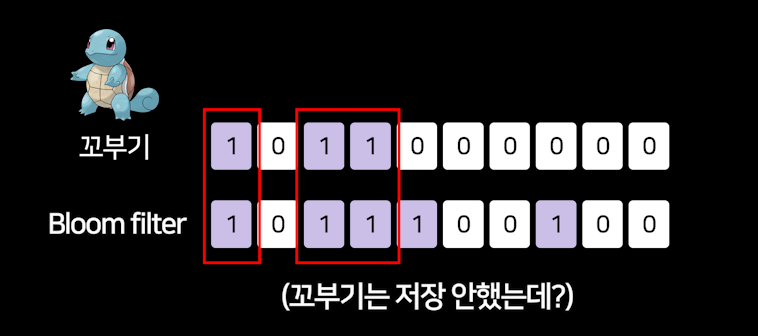
예를 들어 "꼬부기"는 저장 안해놨는데
저장이 되어있다고 판단할 확률이 있다는 것입니다.
멋있는 말로 false positive가 있을 수 있는 것입니다.
자료를 변환하고 겹쳐놨기 때문에 그런 것임
그래서 특정 확률로 자료가 있는지 확인해볼 수 있는 자료구조입니다.
그럼 정확하지 않으니까 아무 쓸데없는 자료구조 아닌가 생각이 들텐데
LLM 같은것도 가끔 정확하지 않은데 쓸모는 많잖아요.
이것도 쓸데있는 분야가 있습니다.
활용
예를 들어 회원가입을 할 때 아이디 존재여부 판단할 때 이런거 쓰면 유용하지 않겠습니까.
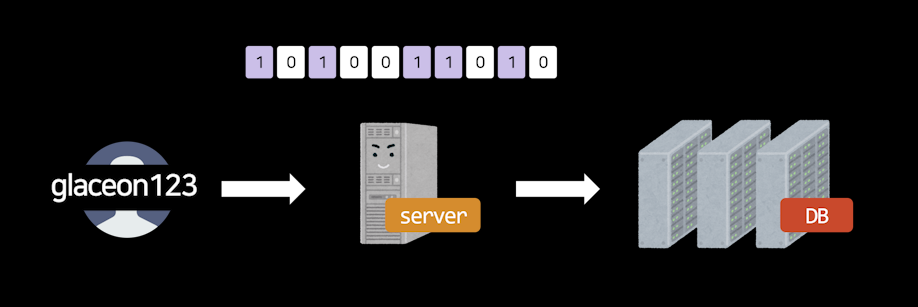
glaceon123 이런 아이디가 들어있는지 검색하려면 원래는 DB를 뒤져야하는데
DB에 있던 아이디를 전부 블룸필터에 쑤셔넣어두면 DB까지 안가도 됩니다.
하지만 아이디가 있다고 나오면 이게 거짓말일 수 있기 때문에 그 때만 DB를 직접 뒤져보면 되겠습니다.
그럼 DB사용량을 획기적으로 줄일 수 있게 됩니다.
크롬은 악성 사이트 URL을 저장하고 검색할때 Bloom Filter를 썼고요
BigTable이랑 SQLite같은 소프트웨어 안에서도 Bloom Filter를 써서 쿼리횟수를 많이 줄이고 있습니다.
예전에 스펠링 체커 같은거 구현할 때도 블룸필터를 이용해서 메모리를 절약했던 경우도 있었고
URL 단축서비스도 이걸 이용해서 메모리 사용량을 99% 줄였다고 합니다.
이거 말고도 캐싱같은걸 구현할 때도 DB를 거치기 전에 앞에 블룸필터를 마련해두면 효율적인 사용이 가능할 것 같습니다.
개선
정확도가 맘에 안들면 블룸필터를 튜닝해서 만들 수 있습니다.
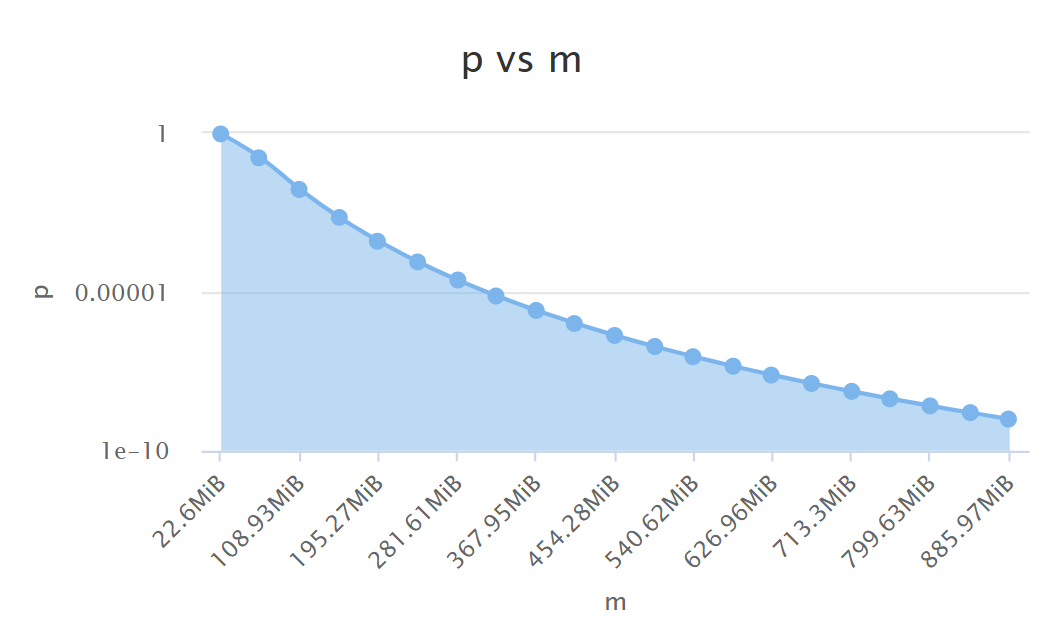
(세로축은 에러확률, 가로축은 비트 갯수)
비트를 몇개 준비할지 해시함수는 몇개 준비할지 이런걸 조절하면 정확도를 올리고 내릴 수 있습니다.
https://hur.st/bloomfilter/?n=100000000&p=0.001&m=&k=10
▲ 궁금하면 계산기를 들어가봅시다.
Ribbon filter라고 성능을 좀 더 개선한 블룸필터도 있고
ngram parser같은걸 넣어서 단어 일부검색이 가능하게 만든 블룸필터도 있고
자료 수정 삭제가 가능하게 만들어둔 블룸필터도 있습니다. (원래는 저장만 가능)
그러니까 내 사이트에 유저가 1억명쯤 있으면 도입해봅시다.